안녕하세요. 저는 LINE 포인트 서버쪽 개발을 담당하고 있는 Ohara(@kory1202)입니다.
얼마 전 특정 테이블에서 데이터를 추출하는 코드를 작성했는데요. 함께 일하는 동료가 그 코드를 보더니 '이런 인덱스가 필요하겠다'고 조언해주었습니다. 이 일을 통해 제가 인덱스 관련 지식이 부족하다는 점을 깨닫게 되었는데요. 그래서 이번에 MySQL Workbench의 VISUAL EXPLAIN을 사용하면서 인덱스에 대해 스터디한 내용을 소개해볼까 합니다. VISUAL EXPLAIN은 SQL의 EXPLAIN을 도식화해주기 때문에 어떤 부분이 문제인지, 인덱스를 도입하면 어떤 처리가 개선되는 지 직관적으로 알 수 있습니다. 강력하게 추천합니다.
목차는 다음과 같습니다.
(이번 포스팅에서는 테스트 환경으로 macOS High Sierra 10.13.4와 MySQL 5.6의 InnoDB를 사용합니다.)
인덱스의 기초
인덱스의 구조
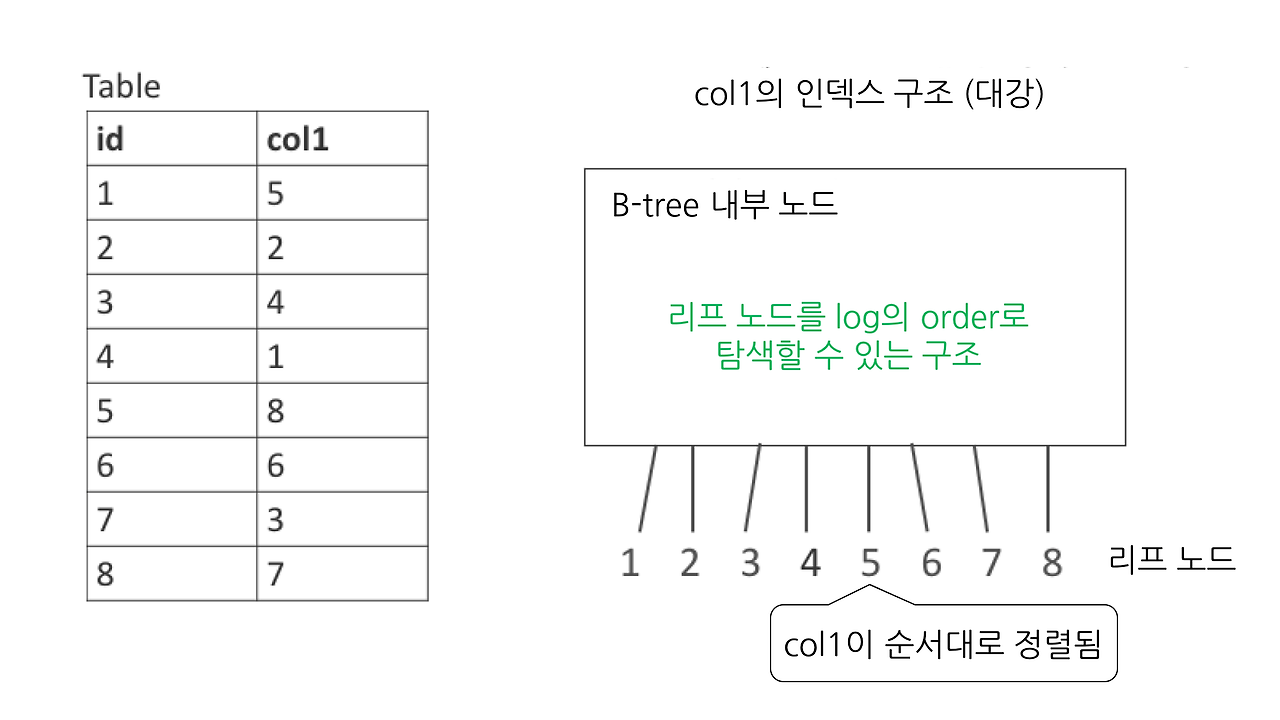
인덱스는 MySQL 5.6, Reference Manual, The Physical Structure of an InnoDB Index에 나와 있듯이, B-tree 구조로 되어 있습니다. 이번 포스팅에서는 B-tree 구조에 대해서 자세히 다루지 않고, 아주 간략한 이미지만 아래에 첨부했습니다.
리프(leaf) 노드는 인덱스로 지정한 컬럼의 오름차순으로 정렬되어 있으며, 실제 행이 어디에 저장되어 있는지에 대한 데이터를 가지고 있습니다. WHERE col1 = 3과 같은 등호 연산이나 WHERE col1 < 2와 같은 범위 검색을 빠른 속도로 처리할 수 있습니다.
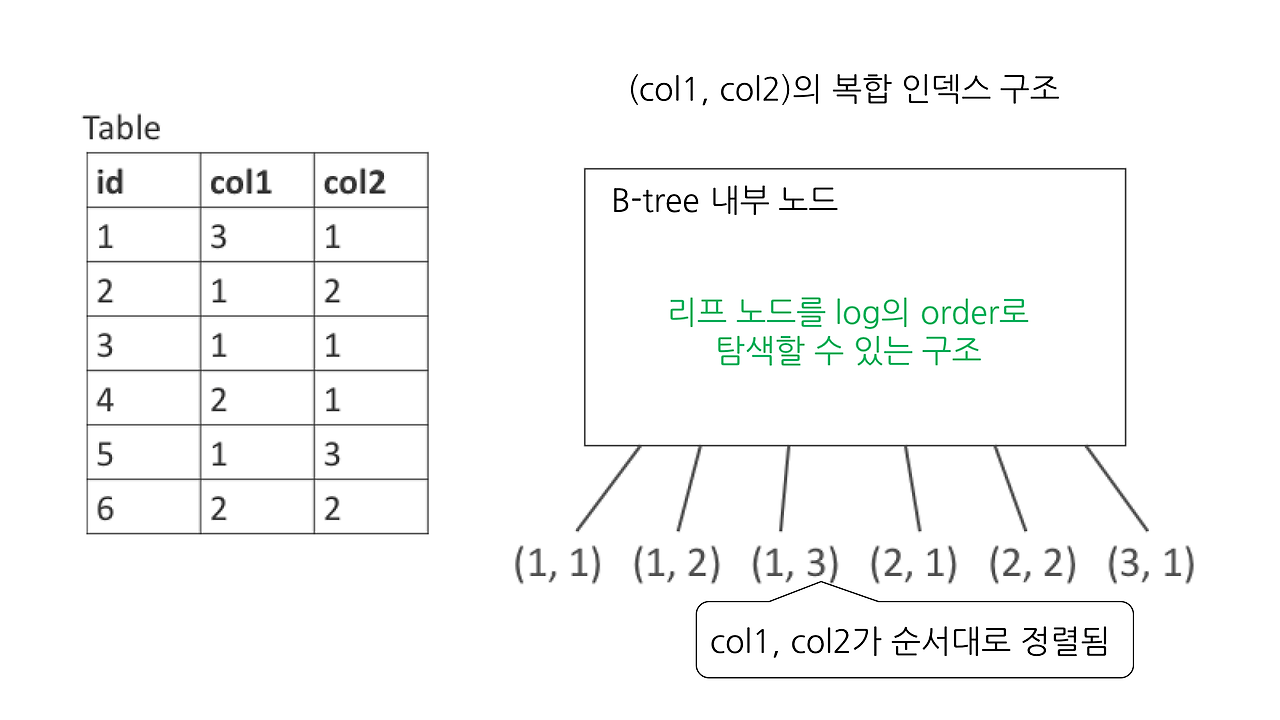
복합 인덱스는 아래 그림처럼 지정한 컬럼 순(여기에서는 col1 col2 순)으로 정렬됩니다. 이렇게 만든 복합인덱스는 WHERE col1 <= 2 조건에는 사용할 수 있지만, WHERE col2 > 1 조건에는 사용할 수 없습니다. col2는 col1 내에서는 정렬되어 있지만, 전체적으로 보았을 때는 정렬되지 않은 상태(그림에서 col2는 왼쪽부터 1 2 3 1 2 1)이기 때문입니다. 따라서, 이 인덱스로는 col2에서 1보다 큰 값이 어디에 있는지 알 수가 없습니다. 마찬가지로, WHERE col1 <= 2 AND col2 >= 2의 경우에도 col1 조건은 트리를 순회하면 탐색할 수 있지만, col2는 트리를 사용해서 찾을 수 없습니다. col1이 정해지면 col2는 정렬된 상태이니, WHERE col1 = 1 AND col2 >= 2에는 사용할 수 있습니다. 이 부분에 대해서는 MySQL with InnoDB 인덱스의 기초 지식과 자주 하는 실수(일본어)도 같이 읽어 보시기 바랍니다.
인덱스 사용법
MySQL 5.6 Reference Manual / 8.3.1 How MySQL Uses Indexes를 꼼꼼히 읽어 보면 주로 사용되는 경우와 추가로 사용 가능한 경우를 알 수 있습니다.
- WHERE와 ORDER BY, GROUP BY를 신속하게 수행하기 위해 사용됨
- 원칙적으로 테이블 하나당 1개의 인덱스가 사용됨
- 테이블의 행 개수는 많고, 검색 결과의 행 개수는 적을 때 사용됨
- 쿼리가 테이블에 적재된 대부분의 행에 접근할 경우에는, 디스크 탐색이 최소화되는 Full Table Scan이 인덱스 사용하는 것보다 속도가 더 빠름
- 따라서, 행 개수가 적은 테이블에서는 Full Table Scan을 사용하는게 좋음
- MySQL5.6 문서에 따르면 테이블 사이즈, 행 개수, I/O 블록 사이즈 등에 따라 인덱스 사용 여부가 결정됨
- 복합 인덱스는 단일 컬럼 인덱스 대용으로도 사용 가능함
- (col1, col2, col3)의 3가지 컬럼 인덱스가 있다면, (col1), (col1, col2), (col1, col2, col3)에 대해 인덱스를 사용할 수 있음
- 데이터 행 참조없이 값을 취득할 수 있는 인덱스(커버링(covering) 인덱스) 사용 시 처리 속도가 향상됨
- 쿼리에 필요한 모든 컬럼을 인덱스가 포함하고 있는 경우가 해당됨
- 예시: column1과 column2가 인덱스에 포함되어 있는 상황일 경우
- 아래 쿼리는 인덱스에서 모든 값을 취득할 수 있기 때문에 데이터 행 확인이 불필요함
-
SELECT column1 FROM tbl_name WHERE column2 = 1;SQL
-
- 아래 쿼리는 데이터 행 확인이 필요함
-
SELECT * FROM tbl_name WHERE column2 = 1;SQL
-
- 아래 쿼리는 인덱스에서 모든 값을 취득할 수 있기 때문에 데이터 행 확인이 불필요함
- 인덱스가 설정된 컬럼에 대해 MAX()나 MIN() 값을 검색하기 위해 사용됨
- 여러 인덱스 중에서 선택할 땐, 행 개수가 가장 적은 것을 검색하는 인덱스 사용함
- 다른 테이블과 JOIN하여 사용할 땐, 컬럼 타입과 사이즈가 동일하면 인덱스를 효율적으로 사용할 수 있음
MySQL Workbench와 VISUAL EXPLAIN 소개
MySQL Workbench는 MySQL의 GUI 클라이언트입니다. GUI에서 인덱스를 추가 및 삭제하거나 ERD(Entity Relationship Diagram)를 그리는 것도 가능하기 때문에, 시행착오를 겪으며 인덱스를 설정할 때 꽤 도움이 됩니다. 그리고 무엇보다 VISUAL EXPLAIN이 가능하다는 사실! 여기에서 'Download Now' 버튼을 클릭하면 다운로드할 수 있습니다.
VISUAL EXPLAIN 실행 방법
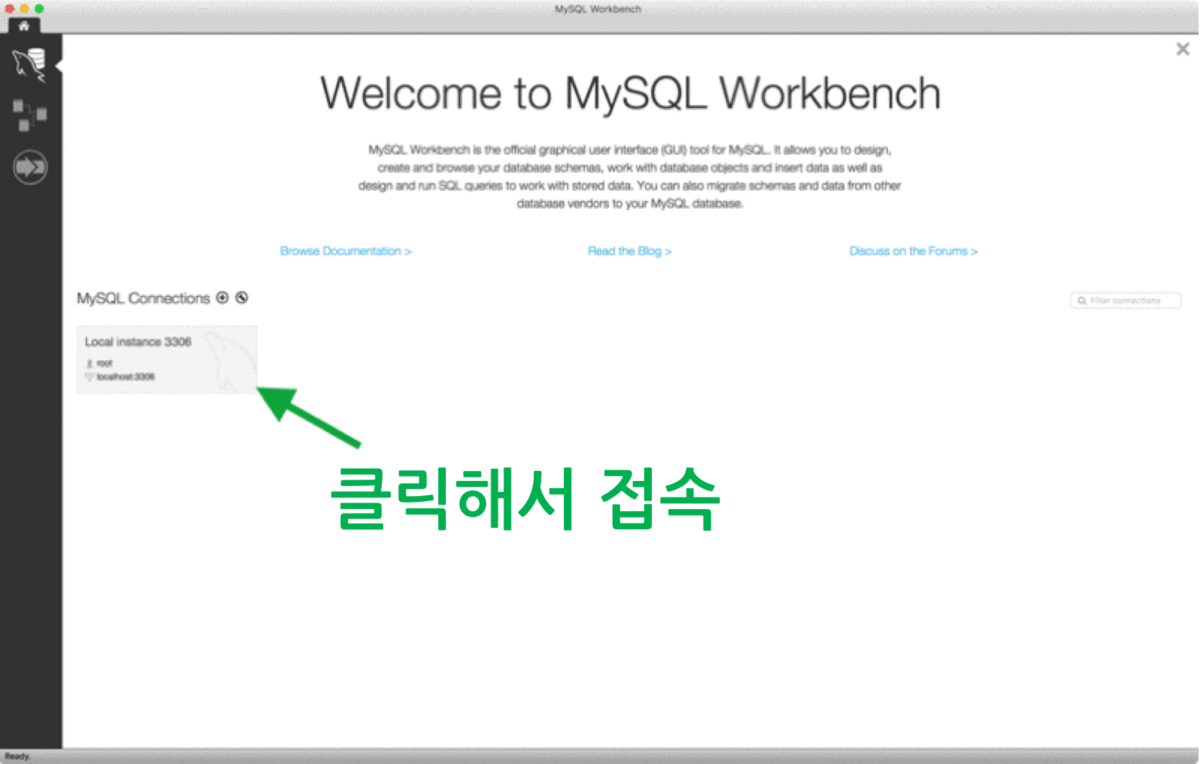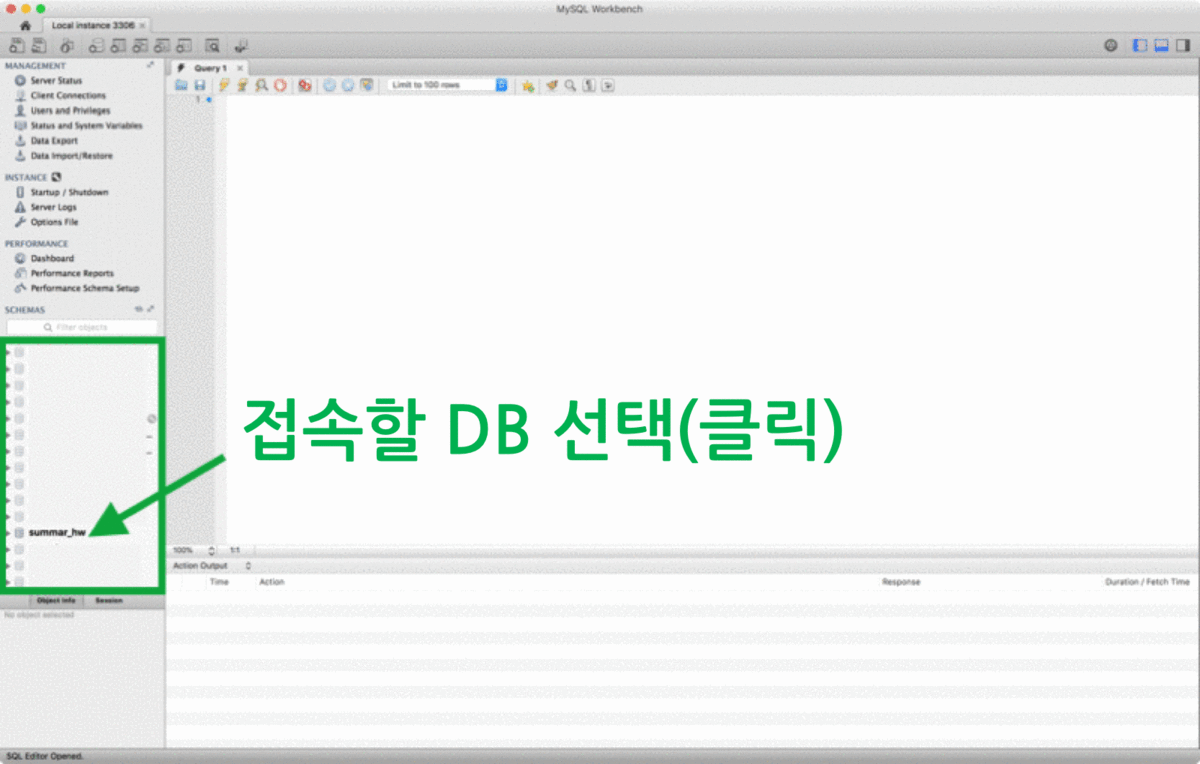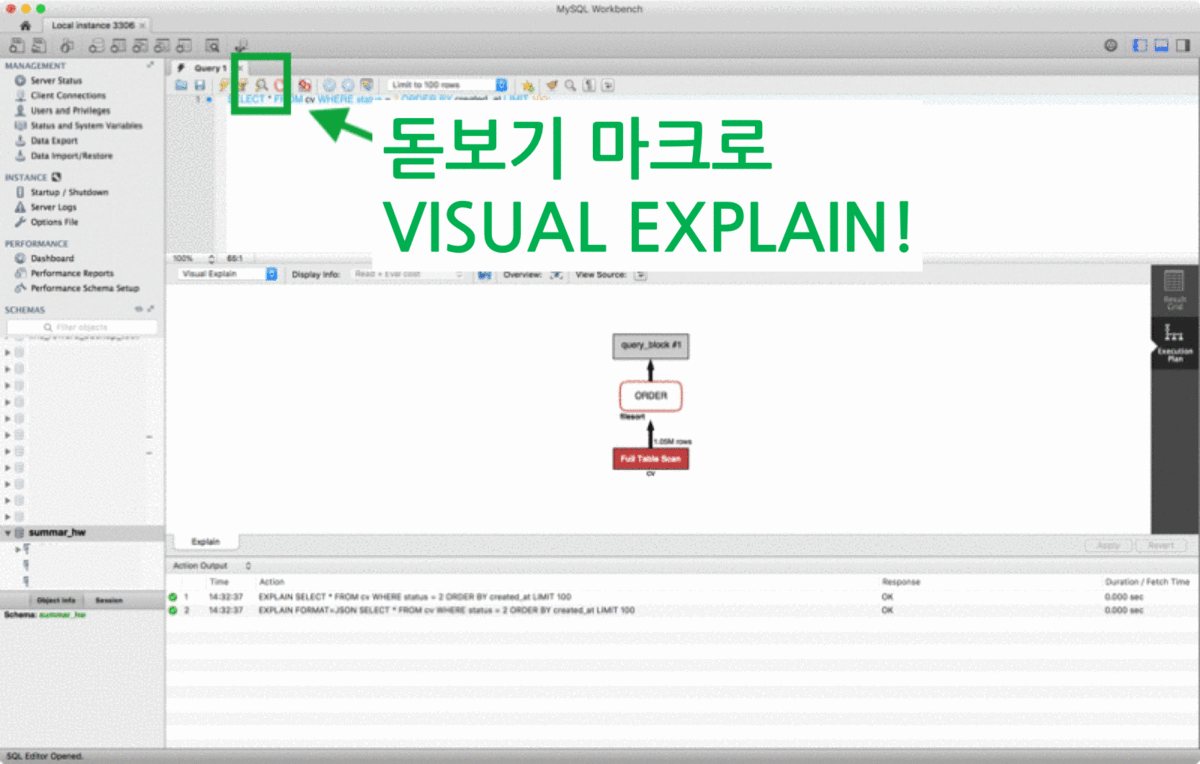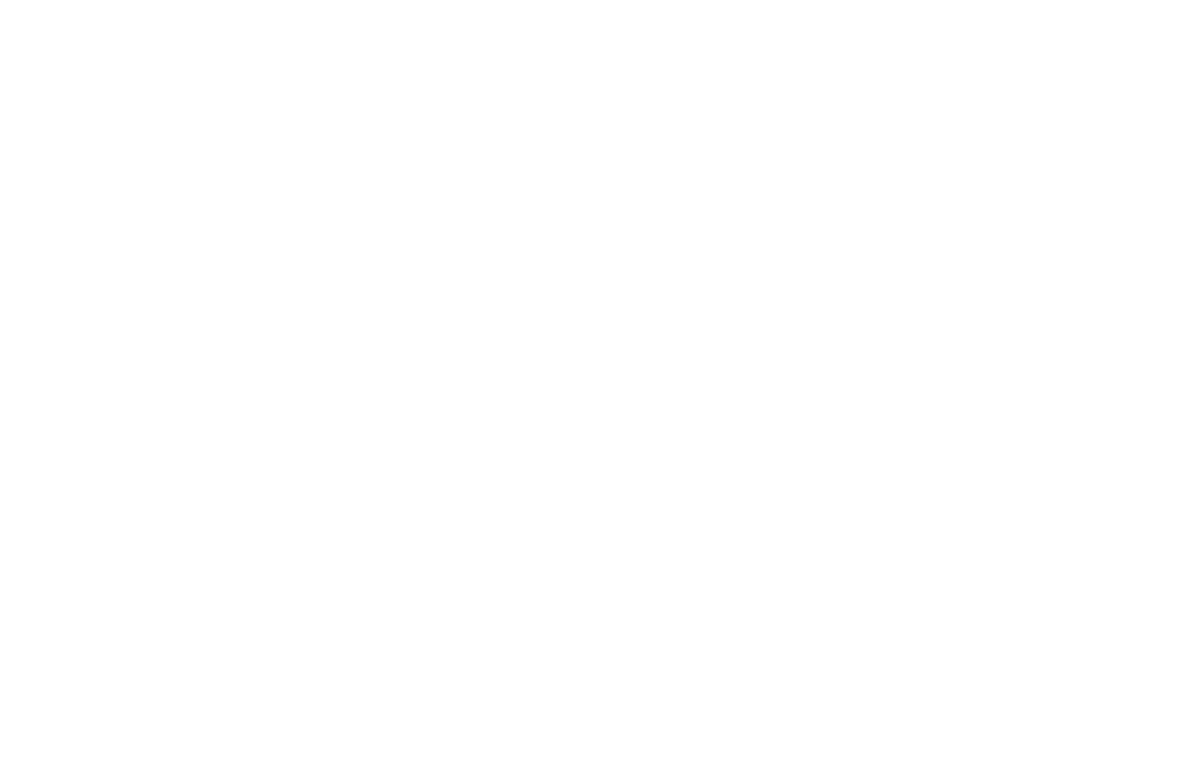
VISUAL EXPLAIN을 실행하려면 쿼리 입력란에 SQL문을 작성하고 왼쪽 상단에 위치한 돋보기 마크나 메뉴의 Query > Explain Current Statement, 또는 단축 키 Cmd + Option + x(macOS의 경우)를 누르면 됩니다.

EXPLAIN 결과가 보고 싶을 때는 위 그림에서 중앙 왼쪽 셀렉트 박스를 변경하면 됩니다. 화면 중앙 오른쪽에 보이는 View Source 버튼을 누르면, VISUAL EXPLAIN의 원래 정보를 JSON 형식으로 확인할 수 있습니다. 사용해보면 참 편리한 기능입니다.
VISUAL EXPLAIN의 색상과 테이블 도형의 텍스트에 대한 간단한 설명
컬러풀한 사각형 오브젝트는 테이블에 어떻게 액세스하는지를 나타냅니다. 파란색에 가까울수록 비용이 낮고, 빨간색에 가까울 수록 비용이 높은 액세스입니다. 아래쪽 빨간색 두 가지, index와 ALL은 인덱스를 활용한 튜닝 대상으로 자주 거론됩니다.
색상오브젝트 내 텍스트EXPLAIN type
| Single row: constant | const | |
| Unique Key Lookup | eq_ref | |
| Non-Unique Key Lookup | ref | |
| Fulltext Index Search | fulltext | |
| Index Range Scan | range | |
| Full Index Scan | index | |
| Full Table Scan | ALL |
(위 표에서 Lookup은 where col = 1과 같은 동등 비교입니다.)
VISUAL EXPLAIN으로 인덱스 동작 확인하기
이제 본론으로 들어가겠습니다. 파란색에서 빨간색으로 갈수록 비용이 커진다는 점만 알고 있으면, 보는 법을 자세하게 기억해 두지 않아도 사용할 수 있습니다.
이번 테스트에 사용할 두 테이블은 어느 사용자가 컨버전했는지 저장해 두는 cv 테이블과 이와 매칭되는 광고의 ad 테이블입니다. 테스트를 위해 만든 데이터의 대략적인 특성은 다음과 같습니다.
- 인덱스가 간단하니, 이 시점에선 PRIMARY KEY만 사용
- 각 테이블에 적재시킨 데이터의 양은 cv가 약 100만 건, ad는 약 4000건
- cv의 status와 ad의 type은 각각 균등하게 10종류씩 설정
- 시간을 저장하는 컬럼은 UNIX TIME, 최근 한 달간의 데이터를 베이스로 저장
ERD는 일부러 MySQL Workbench에서 출력했습니다. Workbench는 외부 키를 지정해 두면 자동으로 relation이 도식화되는데요(참고). 이번에는 설명을 간략화하기 위해 PRIMARY KEY만 지정했기 때문에 아래 그림과 같이 표시되었습니다.
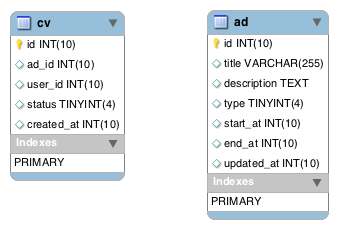
설정된 인덱스 없음
먼저, 설정된 인덱스가 없는 상태를 보시겠습니다.
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;이 쿼리에 대해 VISUAL EXPLAIN을 실행하면 아래 이미지가 나옵니다.
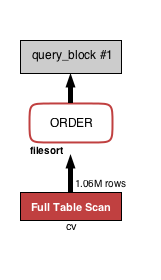
아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
화살표 방향대로 읽으면, cv 테이블 전체를 스캔해서 얻은 100만 개의 행을 ORDER BY로 정렬해서 결과를 얻었다는 것을 알 수 있습니다. 새빨간색이네요. 100만 개나 되는 행을 스캔해서 WHERE 조건에 부합하는 행을 찾고, 전체를 정렬해서 100건을 반환하기 때문에 처리 부하가 큽니다. 인덱스가 필요합니다.
WHERE 조건에 인덱스 설정
위 SQL이 보다 빠르게 처리될 수 있도록 인덱스를 추가하겠습니다.
먼저 WHERE 조건인 status에 인덱스를 지정합니다. 인덱스 덕분에 status = 2인 레코드만 가져오는 것이 쉬워집니다.
ALTER TABLE cv ADD INDEX idx_status (status);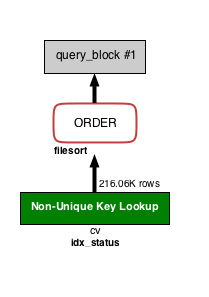
아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
cv 테이블이 초록색으로 변했습니다. 약 21만 건을 가져와서 정렬하기 때문에 앞서 나왔던 100만 건의 경우보다 처리 속도가 상당히 빨라질 듯 합니다. 여기서 21만 건이라는 수치는 MySQL의 예측치이고, 실제로 status = 2인 레코드는 10만 건 정도입니다. 적재된 데이터의 status 컬럼값이 편중되어 있어서 대부분이 status = 2인 상황이라면, 인덱스를 사용하지 않아야 속도가 더 빠르다고 판단되어 Full Table Scan이 수행될 것 같습니다(인덱스 사용법 섹션 참고). 그런 경우라면 ORDER BY에 인덱스를 설정하도록 합시다.
보충 설명: WHERE 조건에 인덱스 설정
적재된 데이터의 status 컬럼값이 편중되어 있어서 대부분이 status = 2인 상황이라면, 인덱스를 사용하지 않아야 속도가 더 빠르다고 판단되어 Full Table Scan이 수행될 것 같습니다.
위 내용을 확인하기 위해 테스트를 했습니다. 테스트는 ANALYZE TABLE cv; 를 실행한 후에 SELECT * FROM cv WHERE status = 2;를 실행하는 방식으로 진행했습니다. 그런데 cv 테이블의 레코드 수가 100만 건일 때는 대부분이 아니라 모든 레코드를 status = 2로 맞춰놓아도 Full Table Scan이 수행되지 않고 status에 지정된 인덱스가 사용되었습니다. 반면에 레코드 수를 약 1만 건으로 줄이니 동일한 쿼리에서 Full Table Scan이 수행되었습니다. 인덱스 사용법 섹션에서 언급했던 것처럼 행 개수에 따라서도 달라지는 것 같습니다.
어쨌든, 여기에서 나오는 status = 2처럼 컬럼 값이 한쪽으로 매우 편중되어 있어서 대부분의 행이 조건에 해당될 때는 인덱스를 달지 않는 것이 좋겠습니다.
ORDER BY 조건에 인덱스 설정
(앞에서 설정한 인덱스는 DROP)
ALTER TABLE cv ADD INDEX idx_created_at (created_at);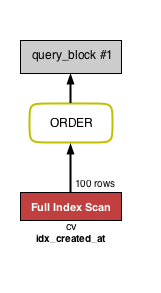
아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
이번에는 ORDER가 연두색이 되었습니다. 테이블은 Full Index Scan입니다. 처리 과정을 설명드리겠습니다.
created_at 인덱스에서 순서대로 레코드를 추출하여 status = 2인지 여부를 확인합니다. 그리고 status = 2인 레코드가 LIMIT 수만큼 발견되었을 때 탐색이 종료될 수 있습니다(created_at에 대해 정렬이 완료되었기 때문). 그래서 예상 취득 레코드 개수도 100개입니다. status = 2인 레코드가 빨리 발견되면 좋겠지만, 마지막까지 발견되지 않으면 인덱스를 전부 읽어야 합니다. status = 2가 드물게 존재하는 경우엔 이런 상황이 벌어지게 되니, status에 인덱스를 설정해서 WHERE로 취득되는 레코드 수를 줄이는 것이 좋을 듯 합니다(개수가 적으면 정렬에 소요되는 비용도 적음). 이 부분은 대충 하는 MySQL 퍼포먼스 튜닝(일본어)에 알기 쉽게 정리되어 있습니다. 참고하시면 좋을 것 같습니다.
WHERE 조건과 ORDER BY 조건 중 어느 쪽에 인덱스를 지정하는 것이 좋을지는 status가 편중되어 있는 정도를 보고 판단하는 것이 좋겠습니다. 아니면 idx_status와 idx_created_at 양쪽 모두에 달아 보고 어느 쪽에서 사용되는지를 확인하는 것도 괜찮습니다. 이번 경우에는 양쪽에 지정하니 idx_created_at가 선택되었습니다. 단, ORDER BY 조건에 인덱스를 지정할 경우, LIMIT 수가 커지면 WHERE 조건에 맞는 레코드를 찾기 위해 많은 행을 읽어야 하는 상황이 벌어집니다. 반면에, WHERE 조건에 지정한 인덱스를 사용하는 경우에는 LIMIT 수가 탐색에 드는 비용에 영향을 미치지 않기 때문에 LIMIT 수가 클 때는 idx_status가 더 좋습니다. 이번 데이터를 쭉 확인해 보니, 대략 LIMIT 2100보다 커지면 idx_status가 사용되었습니다.
GROUP BY 조건에 인덱스 설정
(앞에서 설정한 인덱스는 DROP)
SELECT ad_id, COUNT(*) FROM cv WHERE status = 2 GROUP BY ad_id;ad_id별로 cv의 수를 확인하는 쿼리입니다. 인덱스가 없는 경우에는 아래 그림처럼 빨간색이 됩니다.
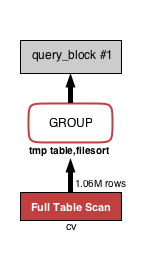
아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
GROUP BY 조건인 ad_id에 인덱스를 지정하면 아래 그림처럼 GROUP BY가 연두색이 됩니다.
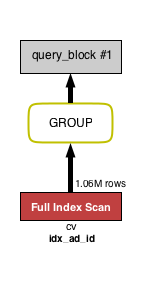
아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
위 그림과 아래 그림을 비교하면 GROUP 밑에 있었던 tmp table, filesort가 사라졌습니다.
GROUP BY 때 왜 인덱스를 사용하는지 설명드리겠습니다. 인덱스를 지정하지 않으면 테이블 전체를 스캔한 후, 각 그룹의 모든 행이 연속적인 상태인 임시 테이블(tmp table)을 생성하여(이때 정렬(filesort)이 필요함), 이 테이블에서 그룹을 찾아내는 처리가 진행됩니다(MySQL 5.6 Reference Manual / GROUP BY Optimization). 위 그림을 보시면 인덱스가 임시 테이블의 역할을 해주어서 이와 같은 처리가 불필요해졌다는 점을 알 수 있습니다.
다만, GROUP BY 처리는 빨라지는 반면에 테이블 접근은 Full Index Scan이어서 처리 부하가 커지니, WHERE 조건에 인덱스를 지정하는 방법을 검토하는 게 좋겠습니다.
복합 인덱스 설정
(앞에서 설정한 인덱스는 DROP)
ALTER TABLE cv ADD INDEX idx_status_created_at (status, created_at);인덱스를 설정하여 다시 아래의 SQL을 VISUAL EXPLAIN합니다.
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;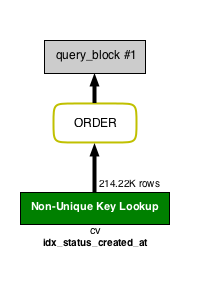
아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
테이블 접근과 ORDER 모두 초록색으로 되어 있는 바람직한 상태입니다(표 형식의 EXPLAIN과 비교해 봤을 때, VISUAL EXPLAIN은 어떤 부분을 개선했는지 한눈에 볼 수 있다는 점이 좋습니다).
연습: 더 복잡한 예
(앞에서 설정한 인덱스는 DROP)
컨버전 수를 일주일 전부터 카운트하여, 카운트 수가 많은 순서대로 ad 테이블의 레코드를 정렬하는 쿼리를 살펴 보겠습니다. 추출하려는 데이터의 상세 조건은 cv의 status는 1, ad의 type은 2입니다.
SELECT
ad.id,
COUNT(DISTINCT cv.user_id) as cv_count
FROM
ad
INNER JOIN cv
ON cv.ad_id = ad.id
AND cv.status = 1
AND cv.created_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY)
WHERE
ad.type = 2
AND ad.end_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY)
GROUP BY
ad.id
ORDER BY
cv_count DESC
LIMIT 100
;위 쿼리를 VISUAL EXPLAIN하니 아래와 같은 이미지가 나왔습니다.

아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
조금 복잡해졌는데요. VISUAL EXPLAIN 결과는 왼쪽 아래에서 오른쪽 위 방향으로 처리가 진행되도록 그림이 그려져 있습니다. 따라서, 왼쪽 아래부터 보시면 됩니다. 이 그림을 보고 알 수 있는 점은 다음과 같습니다.
- JOIN이 nested loop로 처리됨
- nested loop에 대해서는 아래 참고
- driving table 행 하나당 inner table 1행씩 스캔해서 결합 조건에 부합하는 것을 추출함
- cv 테이블에서 읽은 행과 대응되는 ad 테이블의 행을 PRIMARY KEY를 사용해서 읽음
- cv 테이블이 바깥쪽 루프(driving table, outer table)
- ad 테이블이 안쪽 루프(inner table)
- buffer_result라는 임시 테이블이 생성됨
- 임시 테이블을 사용해서 GROUP BY 처리
- 마지막으로 ORDER BY 처리
(아래 내용은 인덱스를 어떻게 지정할 지 고민하면서 시행착오를 겪었던 것을 적은 것인데요. 제 경험을 적은 것일 뿐이고 꼭 이렇게 해야 한다는 의미는 아닙니다. 하나의 예로 봐 주시면 좋겠습니다.)
위 그림을 보면, 우선 cv 테이블의 Full Table Scan을 중단시키고 싶습니다. 그리고 ad 테이블도 결과가 초록색이고 PRIMARY KEY를 사용하고 있긴 하지만, type이나 end_at으로 ad 테이블 자체에 조건을 걸때는 인덱스로 사용할 수 없어서 속도가 느려질 수밖에 없습니다. 따라서, ad쪽에도 인덱스를 생성하여 결과를 살펴보겠습니다.
아래와 같은 인덱스를 설정하고 과연 어떤 것이 사용되는지 확인해 보았습니다.
- cv 테이블
- idx_status_created_at: (status, created_at)
- cv 테이블의 작업 범위 결정 조건으로 사용
- idx_ad_id_status_created_at: (ad_id, status, created_at)
- cv에 관한 조건 순으로 지정
- ad 테이블
- idx_type_end_at: (type, end_at)
- ad 테이블의 작업 범위 결정 조건으로 사용
이 상태로 VISUAL EXPLAIN을 실행하면 아래와 같이 나옵니다.

아래는 위 VISUAL EXPLAIN을 EXPLAIN으로 보았을 때 나타나는 표입니다.
ad와 cv의 위치가 바뀌는 등 여러 군데가 변경되면서 개선되었습니다. 이 그림을 보고 알 수 있는 점은 다음과 같습니다.
- ad 테이블이 driving table이 되고 type이나 end_at의 조건을 지정하기 위해 idx_type_end_at 인덱스가 사용됨
- cv 테이블의 idx_ad_id_status_created_at을 사용하여 ad 테이블에 대응되는 행을 읽음
- cv에 관한 status나 created_at의 조건이 이 인덱스로 지정되었는지는 알 수 없음
- 임시 테이블 buffer_result가 삭제되고 GROUP BY의 tmp table도 삭제됨(GROUP BY는 색상도 오렌지로 바뀜)
임시 테이블인 buffer_result가 삭제된 이유는 GROUP BY 조건이 driving table(이중 루프의 바깥쪽)의 ad.id라서, 미리 정렬한 다음 루프를 실행하면 GROUP BY 조건에 인덱스 절에서 설명한 임시 테이블이 불필요해지기 때문인 것으로 생각됩니다(참고: 실제 사례로 배우는 JOIN(NLJ)이 지연되는 이유와 대처법 / 속도 향상이 어려운 JOIN SQL(일본어)).
Inner table에서 GROUP BY를 하려면 임시 테이블이 필수로 있어야 합니다. 실제로 인덱스를 설정하기 전 상태(cv가 driving table인 상태)에서 GROUP BY를 inner table의 ad.id가 아닌 cv.ad_id로 하면 임시 테이블이 생성되지 않습니다.
복합 인덱스를 사용했을 때, 복합 인덱스의 일부만 사용된다면 단일 인덱스를 지정하는 것이 더 좋습니다(예를 들어, cv 테이블에 설정한 인덱스가 ad 테이블과 대응하는 용도로만 사용되는 경우, 즉 ad_id만 사용되는 경우라면 ad_id에 인덱스를 달면 됨). 따라서, JSON 형식으로 바꿔 used_key_parts를 확인합니다. VISUAL EXPLAIN 실행 방법 섹션의 개요도에 나와 있는 대로 View Source를 클릭해서 확인할 수 있습니다.
아래는 View Source로 확인한 JSON입니다. ad 테이블의 인덱스는 전부 다 사용되고 있으며, cv 테이블의 인덱스의 경우 created_at은 사용되지 않고 ad_id와 status가 사용된다는 점을 알 수 있습니다.
즉, cv의 인덱스는 ad_id와 status만 있으면 되기 때문에, 나중에 created_at을 포함하지 않는 인덱스를 만들었습니다.
{
...
"nested_loop": [
{
"table": {
"table_name": "ad",
...
"key": "idx_type_end_at",
"used_key_parts": [
"type",
"end_at"
],
...
},
{
"table": {
"table_name": "cv",
...
"key": "idx_ad_id_status_created_at",
"used_key_parts": [
"ad_id",
"status"
],
...
}
}
]
...
}cv 테이블의 인덱스에서 created_at이 사용되지 않는 이유는, 이번 블로그 포스팅용으로 만든 데이터의 대부분이 created_at 조건을 충족하고 있어서 MySQL이 인덱스 순회보다는 직접 데이터를 보고 판정하는 것이 좋겠다고 판단했기 때문인 것 같습니다.
MySQL 5.6 Reference Manual / 8.3.1 How MySQL Uses Indexes
쿼리로 대부분의 행에 접근해야 하는 경우에는 순차적으로 읽어들이는 것이 인덱스를 이용하는 것보다 빠릅니다.
그 외에도 여러 인덱스를 설정해 봤는데요. 위의 복합 인덱스 조합(ad 테이블에 type과 end_at, cv 테이블에 ad_id와 status)이 가장 속도가 빨랐습니다.
인덱스를 지정한 후 SQL의 duration은 약 0.007sec가 되었으며, 인덱스 설정 전과 비교하면 약 40분의 1로 단축되었습니다.
참고로 같은 결과를 얻기 위해 서브 쿼리를 사용한 SQL도 테스트해 봤는데요. VISUAL EXPLAIN으로 보면 그림이 복잡하고 실행 시간도 오래 걸렸습니다.
마치며
MySQL Workbench의 VISUAL EXPLAIN을 사용해서 인덱스의 동작을 확인해 보았습니다.
VISUAL EXPLAIN은 직관적으로 이해하기 쉬워서 인덱스를 어떻게 지정해야 할지 고민될 때 사용하면 편리한 것 같습니다. 또한, 인덱스 뿐 아니라 복잡한 쿼리를 어떻게 작성해야 할지 고민될 때도, 쿼리를 작성한 뒤 VISUAL EXPLAIN 결과를 확인하여 임시 테이블이 지나치게 많이 생성되지는 않는지 등을 체크하는 용도로 활용할 수 있을 것 같습니다.
저는 이번에 VISUAL EXPLAIN을 알아보면서, SQL을 사용할 때 MySQL 내부에서 어떤 처리가 진행되는지 공부하는 데에도 도움이 되어서 좋았습니다. 꼭 써 보시기 바랍니다!
'DBA' 카테고리의 다른 글
| PostgreSQL / PPAS 기본 아키텍처 (Engine) (0) | 2024.02.26 |
|---|---|
| MySQL 인덱스(Index) 개인 스터디 실습 및 정리 (1) | 2024.02.26 |
| MYSQL 디스크 용량이 거의 다 찼어요 (0) | 2024.02.26 |
| [MySQL] DB 용량 확인, 테이블별 용량 확인 (1) | 2024.02.26 |
| 친절한 SQL 튜닝 스터디 (1) | 2024.02.25 |


댓글